[৭.২] GORM এর প্রয়োগ (Applying GORM)
[৭.২.১] GORM প্যাকেজ এবং ডাটাবেস কানেকশন স্থাপন
যেকোনো প্যাকেজ এবং তাদের ডিপেনডেন্সি নামানো এবং ম্যানেজ করার জন্য আমাদের প্রয়োজন হবে go mod
ফাইলের… এর জন্য আমাদের প্রজেক্ট ডিরেক্টরিতে যেয়ে, প্রজেক্টের একদম রুটে, নিচের কমান্ডটি টার্মিনালে রান করতে হবে-
go mod init <project_name>
GORM নিয়ে কাজ করতে হলে সবার আগে যা করতে হবে তা হচ্ছে অফিসিয়াল GORM প্যাকেজ টা ইন্সটল করা। এজন্য টার্মিনালে যেয়ে রান করতে হবে-
go get gorm.io/gorm
এর মাধ্যমে GORM, তার ডিপেনডেন্সি গুলোর সাথে লোকাল Go Environment এ ডাউনলোড এবং ইন্সটল হয়ে যাবে।
এরপরে যে ডাটাবেস নিয়ে আমরা কাজ করব সেটার ড্রাইভার প্যাকেজ টা নামিয়ে নেব।
- MySQL এর জন্য:
go get -u gorm.io/driver/mysql
- PostgreSQL এর জন্য:
go get -u gorm.io/driver/postgres
- SQLite এর জন্য:
go get -u gorm.io/driver/sqlite
- SQL Server এর জন্য:
go get -u gorm.io/driver/sqlserver
GORM এবং যথাযথ ডাটাবেস ড্রাইভার নামানোর পর Go কোডের মধ্যে এগুলো ইমপোর্ট করতে হবে। উদাহরণ হিসেবে শুধুমাত্র MySQL এর জন্য দেখানো হলো। অন্য ডাটাবেস ড্রাইভারও প্যাকেজের নাম দিয়ে MySQL এর মতই ইমপোর্ট করা যাবে।
import (
"gorm.io/gorm"
"gorm.io/driver/mysql"
)
সবশেষে আমরা ডাটাবেসে কানেক্ট করব। এজন্য একটি কানেকশন string তৈরি করে প্রয়োজনীয় সকল তথ্য পাস করে দেবো এবং এই অনুযায়ী *gorm.DB এর একটি ইন্সট্যান্স তৈরি হবে –
func main() {
dsn := "user:password@tcp(127.0.0.1:3306)/dbname?charset=utf8mb4&parseTime=True&loc=Local"
db, err := gorm.Open(mysql.Open(dsn), &gorm.Config{})
if err != nil {
panic("failed to connect to database")
}
}
[৭.২.২] GORM মডেল
মডেল হচ্ছে Go এর স্ট্রাক্ট, যেখানে সাধারণ টাইপ, পয়েন্টার অথবা কাস্টম টাইপের ভ্যালু নেয়া যায়। উদাহরণস্বরূপ –
type User struct {
ID uint
Name string
Email *string
Age uint8
Birthday *time.Time
MemberNumber sql.NullString
ActivatedAt sql.NullTime
CreatedAt time.Time
UpdatedAt time.Time
}
কনভেনশনঃ
GORM কনফিগারেশনের থেকে কনভেনশনে বেশি পছন্দ করে। যেমন, ডিফল্ট হিসেবে GORM, ID কে Primary key হিসেবে ব্যবহার করে, সাথে টেবিলের নাম Struct এর নামে(snake_cases), ফিল্ডের নাম Struct এর এলিমেন্টের নামে(snake_cases) এবং CreatedAt, UpdatedAt ব্যবহার করে টেবিলের যেকোনো সারির create/update এর সময়ের ট্র্যাক রাখে।
কনভেনশন ফলো করলে খুব কম কনফিগারেশন লেখার প্রয়োজন পড়ে, শুরুর দিকের ছোট খাটো প্রজেক্ট করার ক্ষেত্রে। যেমন, gorm.Model Struct টি GORM এর নিজস্ব এবং এটি ID, CreatedAt, UpdatedAt, DeletedAt ফিল্ড ধারণ করে। সুতরাং মডেল ডিক্লেয়ার করার সময় gorm.Model ব্যবহার করলে এই ফিল্ড গুলো আলাদা ভাবে Struct এ দেয়ার প্রয়োজন নেই-
type User struct {
gorm.Model
Name string
Email string
}
// equals
type User struct {
ID uint `gorm:"primaryKey"`
CreatedAt time.Time
UpdatedAt time.Time
DeletedAt gorm.DeletedAt `gorm:"index"`
Name string
Email string
}
GORM এর ট্যাগ অপশনাল এবং প্রয়োজন অনুসারে ব্যবহার করা যেতে পারে। ট্যাগগুলোর ব্যাপারে আরো জানার জন্য এই লিংকটি কাজে আসবে। আমরা আপাতত মডেল এর আর গভীরে যাবো না। আমাদের বেসিক বোঝার জন্য এতদূর বোঝাই যথেষ্ট।
রিলেশন:
GORM এ অন্যতম বৈশিষ্ট্য হলো যে একাধিক টেবিলের মধ্যে রিলেশন তৈরি করার ক্ষমতা। GORM সাধারণত one-to-one, one-to-many,many-to-many এবং polymorphic associations এর মতো রিলেশন গুলো সাপোর্ট করে থাকে।
One-to-One Relation:
এ ধরণের রিলেশন তৈরি হয় যখন একটি টেবিলের একটি রেকর্ড অপর একটি টেবিলের শুধুমাত্র একটি রেকর্ডের সাথে রিলেশনে থাকে। উদাহরণ হিসেবে নিচে উল্লেখিত User এবং Profile এর Struct দুটিকে দেখা যাক। এখানে একটি Profile এর রেকর্ড শুধুমাত্র একটি User এর সাথে যুক্ত আছে-
type User struct {
gorm.Model
Name string
Profile Profile
}
type Profile struct {
gorm.Model
UserID uint
Address string
}
One-to-Many Relation:
যখন একটি টেবিলের একটি রেকর্ড অপর একটি টেবিলের একাধিক রেকর্ডের সাথে রিলেশন তৈরি করে তখন তাকে One-to-Many রিলেশন বলা হয়। উদাহরণ হিসেবে নিচে উল্লেখিত User এবং Post এর Struct দুটিকে দেখা যাক। এখানে একটি User একাধিক পোস্টের অধিকারী হতে পারে।
type User struct {
gorm.Model
Name string
Posts []Post
}
type Post struct {
gorm.Model
Title string
Content string
UserID uint
}
এছাড়াও Many-to-Many, Polymorphic associations এবং উল্লেখিত রিলেশনগুলোর ব্যবহার এবং প্রয়োগ সম্পর্কে আরো জানার থাকলে এই লিংকটি কাজে আসবে।
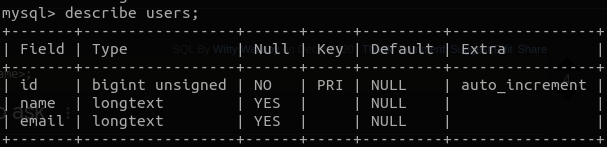
[৭.২.৩] ডাটাবেস টেবিল তৈরি
প্রথমেই একটি Struct তৈরি করে নেই যেটা আমাদের টেবিল স্কিমা হিসেবে কাজ করবে –
type User struct {
ID uint `gorm:"primaryKey;autoIncrement"`
Name string
Email string
}
এবারে GORM এর অটো মাইগ্রেশন ব্যবহার করে টেবিলটি তৈরি করব । AutoMigrate মেথডটি রান করলে, ডাটাবেসের টেবিল তৈরি না থাকলে Struct অনুযায়ী তা তৈরি হয়ে যায়, কোন নতুন ফিল্ড বা ইনডেক্স Struct অনুযায়ী আপডেট হয়ে যায়। কিন্তু এই আপডেটের ফলে ইতোমধ্যেই তৈরি হওয়া ফিল্ড যেমন ডিলেট হয় না তেমনি আগের ডাটাও ডিলেট হয়ে যায় না। বরং নতুন ফিল্ড যোগ হওয়ার ক্ষেত্রে আগের ডাটা গুলোর জন্য ওই ফিল্ডের ভ্যালু হয়ে যায় NULL এবং Struct থেকে ফিল্ড বাদ পড়লে আর ওই ফিল্ডে নতুন ডাটা যোগ হয় না –
// Auto Migrate the table
err = db.AutoMigrate(&User{})
if err != nil {
panic("failed to auto migrate table")
}
তাহলে এই পর্যায়ে কোডটি দাঁড়াচ্ছে –
package main
import (
"gorm.io/gorm"
"gorm.io/driver/mysql"
"gorm.io/gorm/logger"
)
type User struct {
ID uint `gorm:"primaryKey;autoIncrement"`
Name string
Email string
}
func main() {
// Connect to the MySQL database
dsn := "user:password@tcp(localhost:3306)/dbname?charset=utf8mb4&parseTime=True&loc=Local"
db, err := gorm.Open(mysql.Open(dsn), &gorm.Config{
Logger: logger.Default.LogMode(logger.Info),
// logger.Info এর কারণে কুয়েরি গুলো স্ট্যান্ডার্ড
// আউটপুটে প্রিন্ট হতে থাকবে
})
if err != nil {
panic("failed to connect database")
}
// Auto Migrate the table
err = db.AutoMigrate(&User{})
if err != nil {
panic("failed to auto migrate table")
}
}
এটা রান করার পর আমরা আমাদের কাঙ্খিত টেবিল পেয়ে যাবো…
[৭.২.৪] CRUD অপারেশন
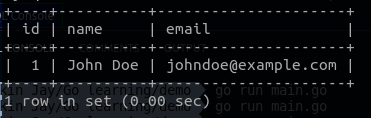
- নতুন “User” তৈরির জন্য (Create) :
// Create a new user
singleUser := User{Name: "John Doe", Email: "johndoe@example.com"}
result := db.Create(&singleUser)
//INSERT INTO `users` (`name`,`email`) VALUES ("John Doe","johndoe@example.com")
if result.Error != nil {
log.Fatal("failed to create user")
}
fmt.Println("Rows affected : ", result.RowsAffected)
fmt.Println("Auto generated user ID : ", singleUser.ID)
// Rows effected : 1
// Auto generated user ID : 1
}
- একাধিক নতুন “User” একসাথে তৈরির জন্য (Bulk Create) :
userArray := []User{
{Name: "Shon Doe", Email: "johndoe@example.com"},
{Name: "Don Doe", Email: "johndoe@example.com"},
{Name: "Von Doe", Email: "johndoe@example.com"},
{Name: "Gone Doe", Email: "johndoe@example.com"},
}
result := db.Create(&singleUser)
if result.Error != nil {
log.Fatal("failed to create any user")
}
- Create এর জন্য আমাদের পয়েন্টার পাস করার কারণ হলো, যদি কোন Auto generated ফিল্ড থেকে থাকে তাহলে Create করার পর উক্ত পয়েন্টার অবজেক্টের ওই ফিল্ড গুলোতেও ওই ভ্যালু আপডেট হয়ে যাবে। যেমনটা হয়েছে আমাদের ID এর ক্ষেত্রে। Create হওয়ার পর ID এর ভ্যালু ডাটাবেসের ভ্যালু অনুযায়ী সেট হয়ে যাচ্ছে।
- Create বা যেকোনো ডাটাবেস অপারেশন রান করার পর সেটা কতগুলো সারিতে ইফেক্ট ফেলেছে সেটা RowsAffected মেথড দ্বারা চেক করতে পারি।
- “User” চেক করার জন্য (Read) :
// Read a user
var readUser User
result = db.Where("email = ?", "johndoe@example.com").First(&readUser)
// SELECT * FROM users WHERE email = "johndoe@example.com";
if result.Error != nil {
panic("failed to read user")
}
fmt.Printf("User: %v\n", readUser)
//Read All users
var readAllUser []User
result = db.Find(&readAllUser)
// SELECT * FROM users
if result.Error != nil {
panic("failed to read user")
}
fmt.Printf("All Users: %v\n", readAllUser)
fmt.Println("Rows effected : ", result.RowsAffected)
// Rows effected : 5
- Read করার জন্য প্রথমবারেও Find মেথড ও ব্যবহার করতে পারতাম, কিন্তু সেটা না করার কারণ হলো, Find মেথড রিটার্ন করে একটি স্লাইস, অর্থাৎ দেয়া শর্তের সাথে যতগুলো সারি মিলবে তার সবই Find একটি স্লাইস এর মধ্যে পাস করে দিবে, যেটা সব Users, Read করার সময় হয়েছে । কিন্তু First মেথড, প্রথম যে সারির সাথে শর্ত মিলবে ওটাকেই রিটার্ন করে থাকে, তাই নির্দিষ্ট সারির ডাটা Read করার জন্য আমরা First ব্যবহার করে থাকি এবং অনেকগুলোর জন্য Find।
- দুই ক্ষেত্রেই Read করতে যেয়ে যদি কাঙ্খিত ডাটা টেবিলে না থেকে থাকে, তাহলে First মেথডটি এরর রিটার্ন করবে, কিন্তু Find মেথড কোনো এরর রিটার্ন করবে না।
- “User” আপডেট করার জন্য (Update) :
// Update a user
updateUser := User{ID: readUser.ID, Name: "New Name", Email: "newname@example.com"}
//UPDATE users SET name=“New Name”, email="johndoe@example.com" where id = readUser.ID
result = db.Save(&updateUser)
if result.Error != nil {
panic("failed to update user")
}
- “User” ডিলেট করার জন্য (Delete) :
// Delete a user
result = db.Delete(&updateUser)
// DELETE FROM users WHERE id = readUser.ID;
if result.Error != nil {
panic("failed to delete user")
}
- যদি DeletedAt নামের কোনো ফিল্ড টেবিলে থেকে থাকে তাহলে উপরের Delete মেথড শুধু soft delete করবে । Soft delete এর ক্ষেত্রে যখন কোনো সারি ডিলেট করা হয় তখন না টেবিল থেকে সরিয়ে না ফেলে ওটার DeletedAt ফিল্ডের ভ্যালু NULL থেকে বদলে দেয়া হয়। সেক্ষেত্রে পরবর্তীতে কোনো অপারেশন চললে ওই সারিকে আর Read/write করে না।
- DeletedAt ফিল্ড না থেকে থাকলে তখন সেটা ডিলেট করলে পুরোপুরি হারিয়ে যায় ওই নির্দিষ্ট সারির ডাটা।
- DeletedAt ফিল্ড থাকা সত্ত্বেও, প্রয়োজন অনুসারে Unscoped, ForceDelete এবং Deleted নামের মেথড গুলো ব্যবহার করে Hard ডিলেটের ব্যাপারটা নিয়ন্ত্রণ করা যায়।
package main
import (
"fmt"
"gorm.io/driver/mysql"
"gorm.io/gorm"
)
type User struct {
ID uint `gorm:"primaryKey"`
Name string
Email string
}
func main() {
// Connect to the MySQL database
dsn := "root:191491@tcp(127.0.0.1:3306)/demo?charset=utf8mb4&parseTime=True&loc=Local"
db, err := gorm.Open(mysql.Open(dsn), &gorm.Config{
Logger: logger.Default.LogMode(logger.Info),
})
if err != nil {
panic("failed to connect database")
}
// Auto Migrate the table
err = db.AutoMigrate(&User{})
if err != nil {
panic("failed to auto migrate table")
}
// Create a new user and some users
singleUser := User{Name: "John Doe", Email: "johndoe@example.com"}
result := db.Create(&singleUser)
//INSERT INTO `users` (`name`,`email`) VALUES ("John Doe","johndoe@example.com")
if result.Error != nil {
panic("failed to create user")
}
fmt.Println("Rows effected : ", result.RowsAffected)
fmt.Println("Auto generated user ID : ", singleUser.ID)
// Rows effected : 1
// Auto generated user ID : 1
userArray := []User{
{Name: "Shon Doe", Email: "johndoe@example.com"},
{Name: "Don Doe", Email: "johndoe@example.com"},
{Name: "Von Doe", Email: "johndoe@example.com"},
{Name: "Gone Doe", Email: "johndoe@example.com"},
}
for _, val := range userArray {
result := db.Create(&val)
//INSERT INTO `users` (`name`,`email`) VALUES ("John Doe","johndoe@example.com")
if result.Error != nil {
panic("failed to create user")
}
}
এই পর্যায়ে নতুন “User” তৈরি হবে John Doe নামের এবং johndoe@example.com ইমেইল সহ আরো ৪ টি User।
// Read a user
var readUser User
result = db.Where("email = ?", "johndoe@example.com").First(&readUser)
// SELECT * FROM users WHERE email = "johndoe@example.com";
if result.Error != nil {
panic("failed to read user")
}
fmt.Printf("User: %v\n", readUser)
//Read All users
var readAllUser []User
result = db.Find(&readAllUser)
if result.Error != nil {
panic("failed to read user")
}
fmt.Printf("All Users: %v\n", readAllUser)
fmt.Println("Rows effected : ", result.RowsAffected)
// Rows effected : 5
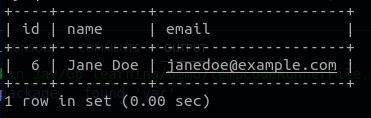
// Update a user
updateUser := User{ID: readUser.ID, Name: "Jane Doe", Email: "janedoe@example.com"}
result = db.Save(&updateUser)
if result.Error != nil {
panic("failed to update user")
}
আপডেটের পর :
// Delete a user
result = db.Delete(&updateUser)
// DELETE FROM users WHERE id = readUser.ID
if result.Error != nil {
panic("failed to delete user")
}
// ডিলেটেড
}
[৭.২.৫] GORM এ Raw SQL
যদিও GORM রিলেশনাল ডাটাবেসের উপর একটা Abstraction লেয়ার দিয়ে থাকে তবুও মাঝে মধ্যে এমন পরিস্থিতি আসতেই পারে যখন Raw SQL কুয়েরি ব্যবহার করার প্রয়োজনীয়তা এসে পড়ে । এমন কয়েকটি পরিস্থিতির উদাহরণ হলো :
- পারফরম্যান্স – কিছু ক্ষেত্রে GORM এর Abstraction এর তুলনায় Raw SQL দ্রুত রান হয়ে থাকে।
- যদি জটিল কুয়েরি রান করতে GORM এর Abstraction ব্যবহার করি সেক্ষেত্রে সেটা ম্যানেজ করাটা কঠিন হয়ে পড়ে। এখানেও Raw SQL সঠিক সিদ্ধান্ত হতে পারে।
- ডাটাবেস স্কিমা তৈরি বা আপডেট করার সময় Raw SQL ব্যবহার করা টা বেশি সহজ ও কার্যকর হয়ে থাকে।
প্রয়োগ :
Raw মেথড ব্যবহার করে আমরা SQL কমান্ড রান করতে পারি এবং Scan মেথড দ্বারা একটি স্লাইস এ কুয়েরির রেজাল্ট গুলো রিটার্ন হিসেবে নেয়া যায় :
db.Raw("SELECT * FROM users WHERE email=?","johndoe@example.com").Scan(&users)
উপরোক্ত কমান্ডটি আমাদের আগের READ কমান্ডটির স্বমতুল্য বলা চলে। পার্থক্য কেবল এই যে, এক্ষেত্রে রিটার্ন হিসেবে একটি স্লাইস পেয়েছি আমরা।
আবার Exec কমান্ডের দ্বারা আমরা এমন সব SQL কমান্ড রান করতে পারি যেগুলোতে কোনো রিটার্ন থাকে না। যেমন, INSERT, UPDATE
db.Exec("UPDATE users SET email = ? WHERE id = ?", "janedoe@example.com", readUser.ID)
উপরোক্ত কমান্ডটি আমাদের আগের Update কমান্ডটির স্বমতুল্য।
Raw SQL সম্পর্কে আরো গভীরভাবে জানার থাকলে এই লিংকটি সহযোগিতা করবে।
[৭.২.৬] ORM যেখানে পিছিয়ে
পারফরমেন্স : GORM মূলত database/sql প্যাকেজের উপর বানানো। database/sql একটি লো-লেভেল ইন্টারফেস হিসেবে কাজ করে, ডাটাবেসের সাথে যোগাযোগ রক্ষার জন্য। এখন GORM এর উপরে যে একটা অ্যাবস্ট্রাকশন লেয়ার আসে, সেটার জন্য কুয়েরি এক্সিকিউট হওয়ার সময়টা তুলনামূলক বেশি হয়।
- মাইগ্রেশন হিস্টোরি : GORM এ যে অটোমাইগ্রেশন বা মাইগ্রেট ফাংশন ব্যবহার করে আমরা ডাটাবেসের গঠন আপ-টু-ডেট রাখি, সেখানে আমাদের আগের মাইগ্রেশনে কি ছিলো বা আগের মাইগ্রেশনে ফেরত যাওয়ার কোনো উপায় GORM এ নেই।
- ডকুমেন্টেশন : GORM এর ডকুমেন্টেশন থেকে অ্যাডভান্সড বিষয়গুলোর প্রয়োগ এবং সমস্যাগুলোর সমাধান সম্পর্কে পরিষ্কার ধারণা পাওয়া যায় না।
